![]()
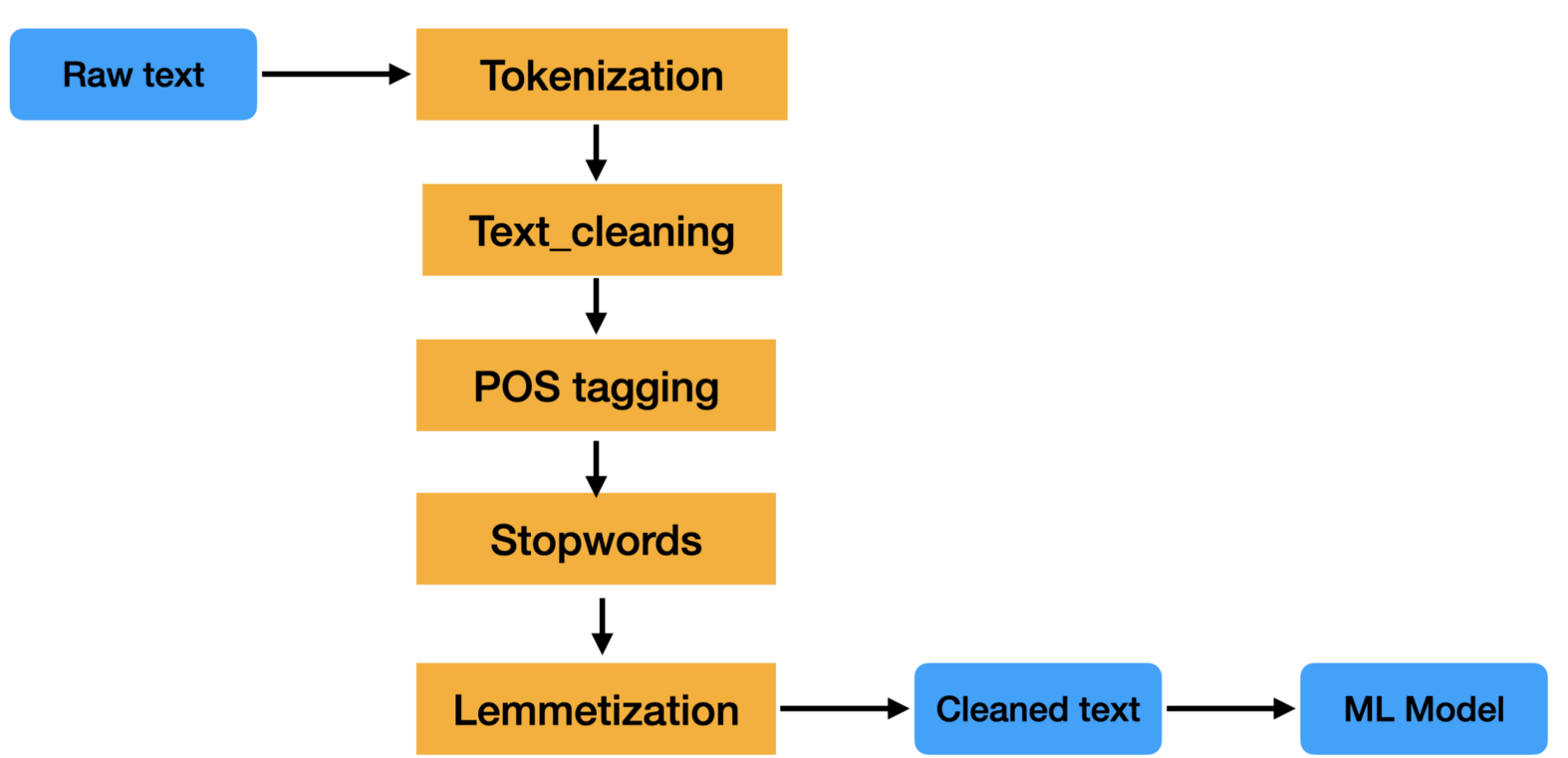
NLP Analysis Pipeline in Opener Library
NLP pipeline implemented in Opener library has the following steps:
- Language Identifier
- Tokenizer
- Stemming
- Part of Speech(POS) Tagger
- Named Entity Recognition(NER)
- Named Entity Linking
Similarly NLTK has the following modules:

Language Identifier
This component is responsible for detecting the language of an input(news article, review) and delivers it to the correct pipeline.
Tokenizer
This component is responsible for tokenizing the text on two levels;
sentence level and word level. This component is crucial for the rest of NLP components and is the first component in each language processing pipeline.
Text Normalization
Stemming and Lemmatization are Text Normalization (or sometimes called Word Normalization) techniques in the field of Natural Language Processing that are used to prepare text, words, and documents for further processing.
Stemming and Lemmatization have been studied, and algorithms have been developed in Computer Science since the 1960’s.
Stemming
The idea of stemming is a sort of normalizing method. Many variations of words carry the same meaning, other than when tense is involved.
The reason why we stem is to shorten the lookup, and normalize sentences. We could reduce each word in documents to their stem using a stemming algorithm like the Porter stemmer.
For example, the semantics of “drawback” and “drawbacks” are so close that distinguishing them will only increase overfitting, and not allow the model to fully exploit the training data.
Similarly, the vocabulary may include words like ‘replace’, ‘replaced’, ‘replacement’, ‘replaces’, ‘replacing’, which are different verb forms and nouns relating to the verb “to replace”.
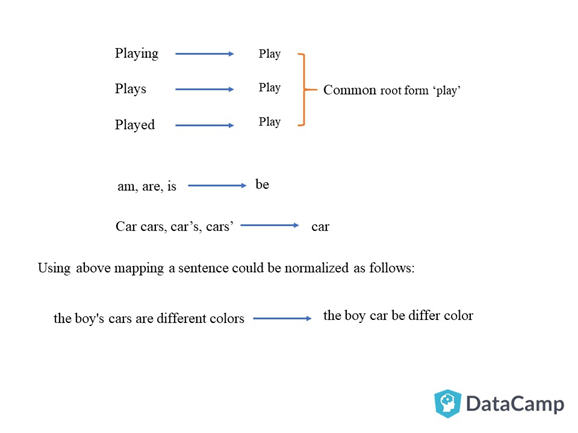
Figure:
Non-English Stemmers
Python nltk provides not only two English stemmers: PorterStemmer and LancasterStemmer but also a lot of non-English stemmers as part of SnowballStemmers, ISRIStemmer, RSLPSStemmer.
Python NLTK included SnowballStemmers as a language to create non-English stemmers.
One can program one’s own language stemmer using snowball. Currently, it supports the following languages: Danish, Dutch, English, French, German, Hungarian, Italian, Norwegian, Porter, Portuguese, Romanian, Russian, Spanish, and Swedish.
ISRIStemmer is an Arabic stemmer and RSLPStemmer is stemmer for the Portuguese Language.
Lemmatization
Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes.
Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma .
If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun.
For example, runs, running, ran are all forms of the word run, therefore run is the lemma of all these words. Because lemmatization returns an actual word of the language, it is used where it is necessary to get valid words.
Python NLTK provides WordNet lemmatizer that uses the WordNet database to lookup lemmas of words.
Applications of Stemming and Lemmatization
Stemming and lemmatization are branches of NLP and are widely used in text mining. Stemming and lemmatization are used as part of the text-preparation process before it is analyzed.
For example, it is used as part of sentiment analysis. Sentiment Analysis is the analysis of people’s reviews and comments about something. It is widely used for analysis of products on online retail shops.
Part of Speech(POS) Tagger
This component is responsible for assigning to each token its morphological label, it also includes the lemmatization of words.
Combining the lemma and morphological label, later modules will consult a sentiment lexicon in order to assign polarity values to the words appearing in the news being processed.
The part of speech explains how a word is used in a sentence. There are eight main parts of speech – nouns, pronouns, adjectives, verbs, adverbs, prepositions, conjunctions and interjections.
- Noun (N)- Daniel, London, table, dog, teacher, pen, city, happiness, hope
- Verb (V)- go, speak, run, eat, play, live, walk, have, like, are, is
- Adjective(ADJ)- big, happy, green, young, fun, crazy, three
- Adverb(ADV)- slowly, quietly, very, always, never, too, well, tomorrow
- Preposition (P)- at, on, in, from, with, near, between, about, under
- Conjunction (CON)- and, or, but, because, so, yet, unless, since, if
- Pronoun(PRO)- I, you, we, they, he, she, it, me, us, them, him, her, this
- Interjection (INT)- Ouch! Wow! Great! Help! Oh! Hey! Hi!
Most POS are divided into sub-classes. POS Tagging simply means labeling words with their appropriate Part-Of-Speech.

Chunking
Chunking a sentence refers to breaking/dividing a sentence into parts of words such as word groups and verb groups.
To chunk a sentence, you need to :
- Tokenize the sentence
- Generate POS tags for it
- Chunk the sentences using the nltk
Text chunking consists of dividing a text in syntactically correlated parts of words. For example, the following sentence:
“He reckons the current account deficit will narrow to only # 1.8 billion in September .”
can be divided as follows:
“[NP He ] [VP reckons ] [NP the current account deficit ] [VP will narrow ] [PP to ] [NP only # 1.8 billion ] [PP in ] [NP September ] .”
Named Entity Recognition(NER)
Truly effective sentiment analysis is a complex NLP task in monolingual contexts alone. In multilingual contexts the complexity increases many-fold and also presents the challenge of comparison of opinion across languages and cultures.
Named entity recognition and classification is also a key element to this challenge. This module provides Named Entity Recognition (NER) for the six languages covered by OpeNER.
This module tries to recognize four types of named entities:
- Persons,
- Locations,
- Organizations
- Names of miscellaneous entities that do not belong to the previous three groups.
Figure : Named Entity Recognition(NER) example
Named Entity Linking
Once the named entities are recognized they can be identified or disambiguated with respect to an existing catalogue. This is required because the “surface form” of a Named Entity can actually refer to several different things in the world.
