![]()
Data Science, Business Intelligence and Data Science can be complicated and costly for any enterprise regardless of size, but it is even more for startups and small organization. Cost of licensing and hardware is big part of that cost.
Greenplum is the first open source massively parallel processing(MPP) database. But it should be noted that Greenplum has over 400 enterprise customers. Greenplum represents more than 10 years of development, and is therefore a mature and reliable technology. Greenplum has great performance and scalability, great extensibility and analytical capabilities.

Main usage of Greenplum columnar data warehouse is of course enabling business intelligence and data science solutions for which traditional relational databases including Oracle are not well suited. There is a fundamental difference between OLTP and OLAP or business intelligence applications.

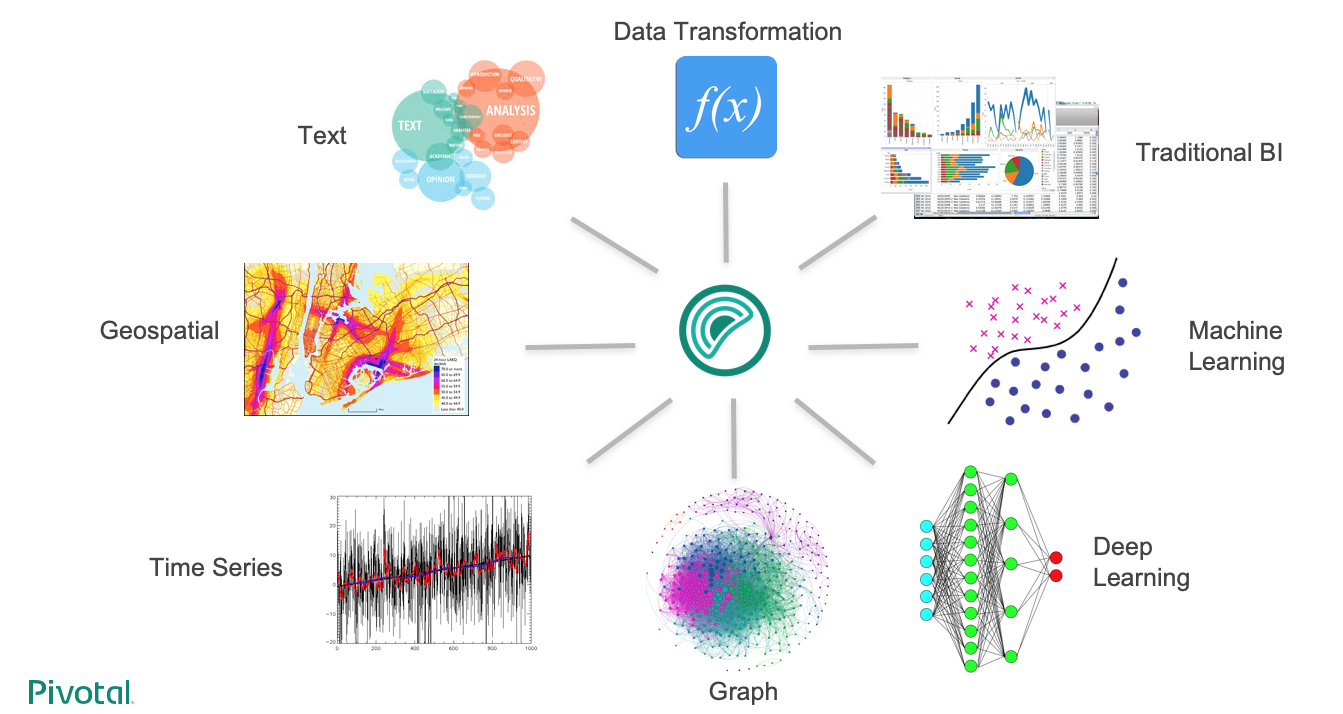
Data science teams prepares and cooks data in Greenplum in a lot of different ways using different tools and technologies such as :
- Procedure Language: PL/Python, PL/R, PL/Container
- GPText
- Apache MADlib

Figure :

GPText
GPText enables organizations to process mass quantities of raw text data for large-scale text analytics. It provides indexing, search, and analytics functions that are exposed as SQL UDFs.
It Integrates with Apache Solr enterprise search. Compute is distributed in segments, can be run in parallel.
MADlib
It is a rich algorithm library with more than 50+ algorithms. It is easy to use SQL based interface for machine learning. MADlib is an open source Apache top project. It is distributed, integrated with Greenplum, and supports MPP architecture. Main advantage and attraction for using MADlib is In-database analysis, which means no additional data movement.

MADlib has many machine learning algorithms:-
- Supervised Learning: Linear Regression, Decision Tree, SVM, CRF etc.
- Un-Supervised Learning: K-Means, LDA, PCA, Association Rule etc.
- Graph: PageRank, HIT, All Pairs Shortest Path, Weakly Connected Components etc.
- Time Series: ARIMA
- Model Selection: Cross Validation, Prediction Metrics
MADlib covers many use cases, including :
- Risk Management
– Credit risk, Operational risk, Market risk - Financial Analysis
– Customer credit, Cash inflow, Key financial ratios/performance - Fraud Detection
– Internal fraud, External fraud - Compliance
– Data integration, Reporting, Audit - Customer Intelligence
– Behavior analysis, Spend & Value analysis, Portfolio analysis, Scorecard and Rating applications - Performance Management
– Analysis of business methodologies, metrics, processes and systems
Greenplum Architecture
The main reason behind adaptation of MPP DWH solution is MPP architectural principles. These principles aim at removing main drawbacks of traditional DWH, and make MPP databases so powerful for large datasets and analytical queries.
- Shared Nothing
- Data Sharding
- Data Replication
- Distributed Transactions
- Parallel Processing
Sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards. The word shard means a small part of a whole.
Database replication is the frequent electronic copying of data from a database in one computer or server to a database in another so that all users share the same level of information. The result is a distributed database in which users can access data relevant to their tasks without interfering with the work of others.
MPP data warehouse works well for:-
- Relational data
- Batch processing
- Ad hoc analytical SQL
- Low concurrency
- Applications requiring ANSI SQL
MPP data warehouse solution is not the best choice for :-
- Non-relational data
- OLTP and event stream processing
- High concurrency as in OLTP
- 100+ server clusters
- Non-analytical use cases
- Geo-Distributed use cases
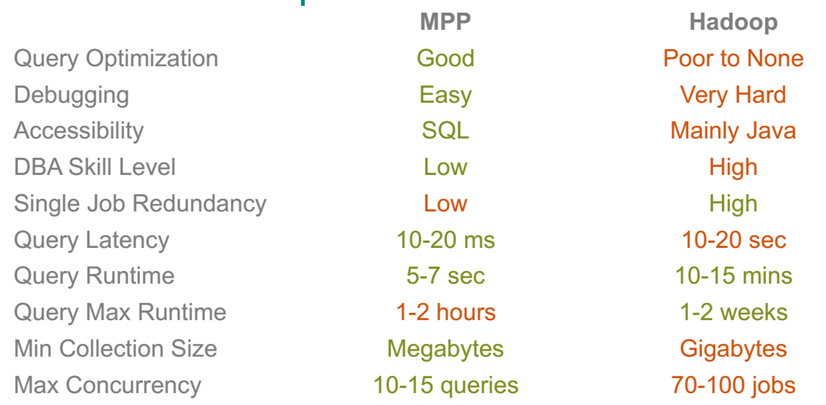
How would you choose between MPP and Hadoop based solution for your analytical workload ?
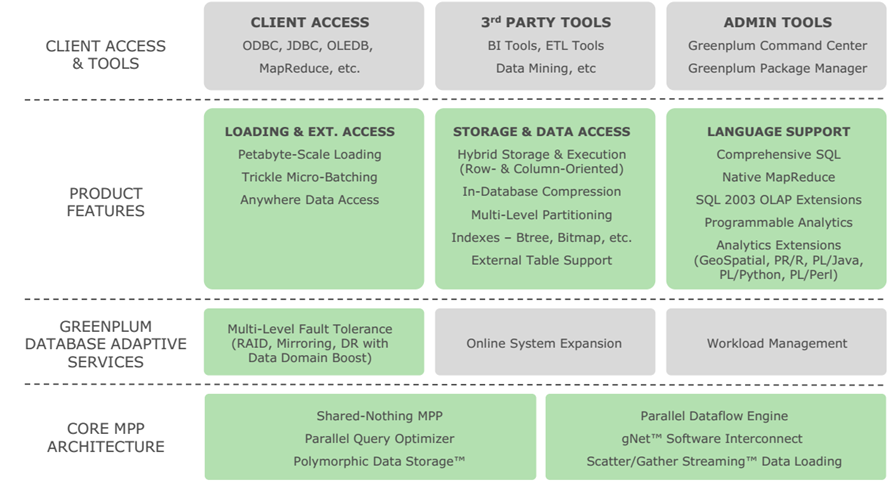
If you chose Greenplum Data Compute Appliance (aka EMC hardware) then here’s an overview of the hardware architecture and performance. You can build/acquire third party hardware for Greenplum as well. Main advantage of Greenplum DCA appliances is of course performance, technical support and timely updates/fixes.
